This is “Comparison of Two Population Means: Small, Independent Samples”, section 9.2 from the book Beginning Statistics (v. 1.0). For details on it (including licensing), click here.
For more information on the source of this book, or why it is available for free, please see the project's home page. You can browse or download additional books there. To download a .zip file containing this book to use offline, simply click here.



9.2 Comparison of Two Population Means: Small, Independent Samples
Learning Objectives
- To learn how to construct a confidence interval for the difference in the means of two distinct populations using small, independent samples.
- To learn how to perform a test of hypotheses concerning the difference between the means of two distinct populations using small, independent samples.
When one or the other of the sample sizes is small, as is often the case in practice, the Central Limit Theorem does not apply. We must then impose conditions on the population to give statistical validity to the test procedure. We will assume that both populations from which the samples are taken have a normal probability distribution and that their standard deviations are equal.
Confidence Intervals
When the two populations are normally distributed and have equal standard deviations, the following formula for a confidence interval for is valid.
Confidence Interval for the Difference Between Two Population Means: Small, Independent Samples
The number of degrees of freedom is
The samples must be independent, the populations must be normal, and the population standard deviations must be equal. “Small” samples means that either or
The quantity is called the pooled sample variance. It is a weighted average of the two estimates and of the common variance of the two populations.
Example 4
A software company markets a new computer game with two experimental packaging designs. Design 1 is sent to 11 stores; their average sales the first month is 52 units with sample standard deviation 12 units. Design 2 is sent to 6 stores; their average sales the first month is 46 units with sample standard deviation 10 units. Construct a point estimate and a 95% confidence interval for the difference in average monthly sales between the two package designs.
Solution:
The point estimate of is
In words, we estimate that the average monthly sales for Design 1 is 6 units more per month than the average monthly sales for Design 2.
To apply the formula for the confidence interval, we must find The 95% confidence level means that α = 1 − 0.95 = 0.05 so that From Figure 12.3 "Critical Values of ", in the row with the heading df = 11 + 6 − 2 = 15 we read that From the formula for the pooled sample variance we compute
Thus
We are 95% confident that the difference in the population means lies in the interval , in the sense that in repeated sampling 95% of all intervals constructed from the sample data in this manner will contain Because the interval contains both positive and negative values the statement in the context of the problem is that we are 95% confident that the average monthly sales for Design 1 is between 18.3 units higher and 6.3 units lower than the average monthly sales for Design 2.
Hypothesis Testing
Testing hypotheses concerning the difference of two population means using small samples is done precisely as it is done for large samples, using the following standardized test statistic. The same conditions on the populations that were required for constructing a confidence interval for the difference of the means must also be met when hypotheses are tested.
Standardized Test Statistic for Hypothesis Tests Concerning the Difference Between Two Population Means: Small, Independent Samples
The test statistic has Student’s t-distribution with degrees of freedom.
The samples must be independent, the populations must be normal, and the population standard deviations must be equal. “Small” samples means that either or
Example 5
Refer to Note 9.11 "Example 4" concerning the mean sales per month for the same computer game but sold with two package designs. Test at the 1% level of significance whether the data provide sufficient evidence to conclude that the mean sales per month of the two designs are different. Use the critical value approach.
Solution:
-
Step 1. The relevant test is
-
Step 2. Since the samples are independent and at least one is less than 30 the test statistic is
which has Student’s t-distribution with degrees of freedom.
-
Step 3. Inserting the data and the value into the formula for the test statistic gives
-
Step 4. Since the symbol in Ha is “≠” this is a two-tailed test, so there are two critical values, From the row in Figure 12.3 "Critical Values of " with the heading we read off The rejection region is
Figure 9.4 Rejection Region and Test Statistic for Note 9.13 "Example 5"
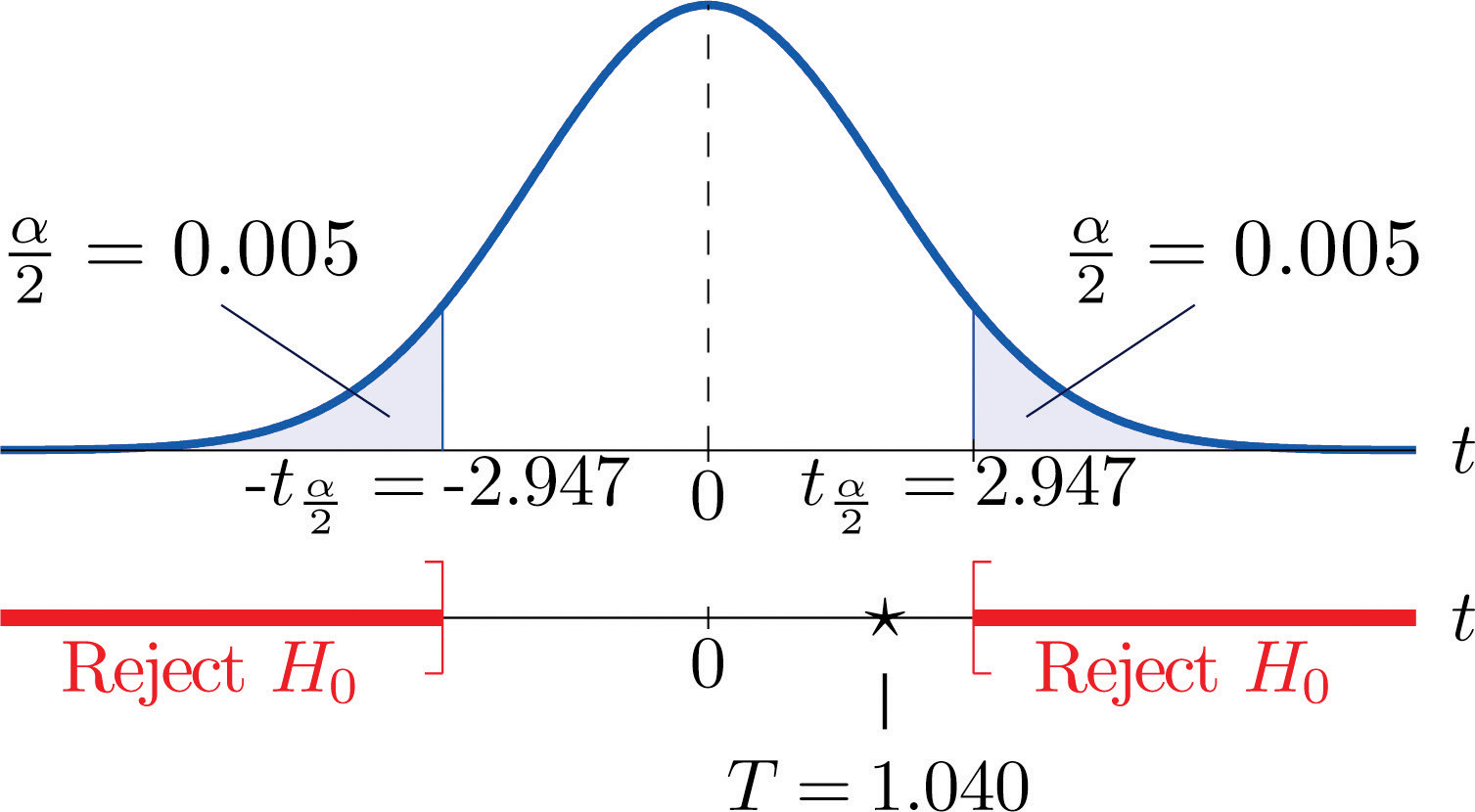
-
Step 5. As shown in Figure 9.4 "Rejection Region and Test Statistic for " the test statistic does not fall in the rejection region. The decision is not to reject H0. In the context of the problem our conclusion is:
The data do not provide sufficient evidence, at the 1% level of significance, to conclude that the mean sales per month of the two designs are different.
Example 6
Perform the test of Note 9.13 "Example 5" using the p-value approach.
Solution:
The first three steps are identical to those in Note 9.13 "Example 5".
-
Step 4. Because the test is two-tailed the observed significance or p-value of the test is the double of the area of the right tail of Student’s t-distribution, with 15 degrees of freedom, that is cut off by the test statistic T = 1.040. We can only approximate this number. Looking in the row of Figure 12.3 "Critical Values of " headed , the number 1.040 is between the numbers 0.866 and 1.341, corresponding to t0.200 and t0.100.
The area cut off by t = 0.866 is 0.200 and the area cut off by t = 1.341 is 0.100. Since 1.040 is between 0.866 and 1.341 the area it cuts off is between 0.200 and 0.100. Thus the p-value (since the area must be doubled) is between 0.400 and 0.200.
-
Step 5. Since , , so the decision is not to reject the null hypothesis:
The data do not provide sufficient evidence, at the 1% level of significance, to conclude that the mean sales per month of the two designs are different.
Key Takeaways
- In the context of estimating or testing hypotheses concerning two population means, “small” samples means that at least one sample is small. In particular, even if one sample is of size 30 or more, if the other is of size less than 30 the formulas of this section must be used.
- A confidence interval for the difference in two population means is computed using a formula in the same fashion as was done for a single population mean.
Exercises
-
Construct the confidence interval for for the level of confidence and the data from independent samples given.
-
95% confidence,
, ,
, ,
-
99% confidence,
, ,
, ,
-
-
Construct the confidence interval for for the level of confidence and the data from independent samples given.
-
90% confidence,
, ,
, ,
-
99% confidence,
, ,
, ,
-
-
Construct the confidence interval for for the level of confidence and the data from independent samples given.
-
99.9% confidence,
, ,
, ,
-
99% confidence,
, ,
, ,
-
-
Construct the confidence interval for for the level of confidence and the data from independent samples given.
-
99.5% confidence,
, ,
, ,
-
99.9% confidence,
, ,
, ,
-
-
Perform the test of hypotheses indicated, using the data from independent samples given. Use the critical value approach.
-
Test vs. @ ,
, ,
, ,
-
Test vs. @ ,
, ,
, ,
-
-
Perform the test of hypotheses indicated, using the data from independent samples given. Use the critical value approach.
-
Test vs. @ ,
, ,
, ,
-
Test vs. @ ,
, ,
, ,
-
-
Perform the test of hypotheses indicated, using the data from independent samples given. Use the critical value approach.
-
Test vs. @ ,
, ,
, ,
-
Test vs. @ ,
, ,
, ,
-
-
Perform the test of hypotheses indicated, using the data from independent samples given. Use the critical value approach.
-
Test vs. @ ,
, ,
, ,
-
Test vs. @ ,
, ,
, ,
-
-
Perform the test of hypotheses indicated, using the data from independent samples given. Use the p-value approach. (The p-value can be only approximated.)
-
Test vs. @ ,
, ,
, ,
-
Test vs. @ ,
, ,
, ,
-
-
Perform the test of hypotheses indicated, using the data from independent samples given. Use the p-value approach. (The p-value can be only approximated.)
-
Test vs. @ ,
, ,
, ,
-
Test vs. @ ,
, ,
, ,
-
-
Perform the test of hypotheses indicated, using the data from independent samples given. Use the p-value approach. (The p-value can be only approximated.)
-
Test vs. @ ,
, ,
, ,
-
Test vs. @ ,
, ,
, ,
-
-
Perform the test of hypotheses indicated, using the data from independent samples given. Use the p-value approach. (The p-value can be only approximated.)
-
Test vs. @ ,
, ,
, ,
-
Test vs. @ ,
, ,
, ,
-
Basic
In all exercises for this section assume that the populations are normal and have equal standard deviations.
-
A county environmental agency suspects that the fish in a particular polluted lake have elevated mercury level. To confirm that suspicion, five striped bass in that lake were caught and their tissues were tested for mercury. For the purpose of comparison, four striped bass in an unpolluted lake were also caught and tested. The fish tissue mercury levels in mg/kg are given below.
- Construct the 95% confidence interval for the difference in the population means based on these data.
- Test, at the 5% level of significance, whether the data provide sufficient evidence to conclude that fish in the polluted lake have elevated levels of mercury in their tissue.
-
A genetic engineering company claims that it has developed a genetically modified tomato plant that yields on average more tomatoes than other varieties. A farmer wants to test the claim on a small scale before committing to a full-scale planting. Ten genetically modified tomato plants are grown from seeds along with ten other tomato plants. At the season’s end, the resulting yields in pound are recorded as below.
- Construct the 99% confidence interval for the difference in the population means based on these data.
- Test, at the 1% level of significance, whether the data provide sufficient evidence to conclude that the mean yield of the genetically modified variety is greater than that for the standard variety.
-
The coaching staff of a professional football team believes that the rushing offense has become increasingly potent in recent years. To investigate this belief, 20 randomly selected games from one year’s schedule were compared to 11 randomly selected games from the schedule five years later. The sample information on rushing yards per game (rypg) is summarized below.
n s rypg previously 20 112 24 rypg recently 11 114 21 - Construct the 95% confidence interval for the difference in the population means based on these data.
- Test, at the 5% level of significance, whether the data on rushing yards per game provide sufficient evidence to conclude that the rushing offense has become more potent in recent years.
-
The coaching staff of professional football team believes that the rushing offense has become increasingly potent in recent years. To investigate this belief, 20 randomly selected games from one year’s schedule were compared to 11 randomly selected games from the schedule five years later. The sample information on passing yards per game (pypg) is summarized below.
n s pypg previously 20 203 38 pypg recently 11 232 33 - Construct the 95% confidence interval for the difference in the population means based on these data.
- Test, at the 5% level of significance, whether the data on passing yards per game provide sufficient evidence to conclude that the passing offense has become more potent in recent years.
-
A university administrator wishes to know if there is a difference in average starting salary for graduates with master’s degrees in engineering and those with master’s degrees in business. Fifteen recent graduates with master’s degree in engineering and 11 with master’s degrees in business are surveyed and the results are summarized below.
n s Engineering 15 68,535 1627 Business 11 63,230 2033 - Construct the 90% confidence interval for the difference in the population means based on these data.
- Test, at the 10% level of significance, whether the data provide sufficient evidence to conclude that the average starting salaries are different.
-
A gardener sets up a flower stand in a busy business district and sells bouquets of assorted fresh flowers on weekdays. To find a more profitable pricing, she sells bouquets for 15 dollars each for ten days, then for 10 dollars each for five days. Her average daily profit for the two different prices are given below.
n s $15 10 171 26 $10 5 198 29 - Construct the 90% confidence interval for the difference in the population means based on these data.
- Test, at the 10% level of significance, whether the data provide sufficient evidence to conclude the gardener’s average daily profit will be higher if the bouquets are sold at $10 each.
Applications
Answers
-
- ,
-
-
- ,
-
-
- T = 2.787, , reject H0,
- T = 1.831, , do not reject H0
-
-
- , , reject H0,
- T = 1.411, , do not reject H0
-
-
- T = 2.411, , , do not reject H0,
- T = 1.473, , , reject H0
-
-
- T = 2.827, , , reject H0.
- T = 1.699, , , reject H0
-
-
- ,
- T = 3.635, , , reject H0 (elevated levels)
-
-
- ,
- , , , do not reject H0 (not more potent)
-
-
- ,
- T = 7.395, , , reject H0 (different)
-