This is “Data Warehouses and Data Marts”, section 11.5 from the book Getting the Most Out of Information Systems (v. 1.4). For details on it (including licensing), click here.
For more information on the source of this book, or why it is available for free, please see the project's home page. You can browse or download additional books there. To download a .zip file containing this book to use offline, simply click here.



11.5 Data Warehouses and Data Marts
Learning Objectives
- Understand what data warehouses and data marts are and the purpose they serve.
- Know the issues that need to be addressed in order to design, develop, deploy, and maintain data warehouses and data marts.
Since running analytics against transactional data can bog down a system, and since most organizations need to combine and reformat data from multiple sources, firms typically need to create separate data repositories for their reporting and analytics work—a kind of staging area from which to turn that data into information.
Two terms you’ll hear for these kinds of repositories are data warehouseA set of databases designed to support decision making in an organization. and data martA database or databases focused on addressing the concerns of a specific problem (e.g., increasing customer retention, improving product quality) or business unit (e.g., marketing, engineering).. A data warehouse is a set of databases designed to support decision making in an organization. It is structured for fast online queries and exploration. Data warehouses may aggregate enormous amounts of data from many different operational systems.
A data mart is a database focused on addressing the concerns of a specific problem (e.g., increasing customer retention, improving product quality) or business unit (e.g., marketing, engineering).
Marts and warehouses may contain huge volumes of data. For example, a firm may not need to keep large amounts of historical point-of-sale or transaction data in its operational systems, but it might want past data in its data mart so that managers can hunt for patterns and trends that occur over time.
Figure 11.2
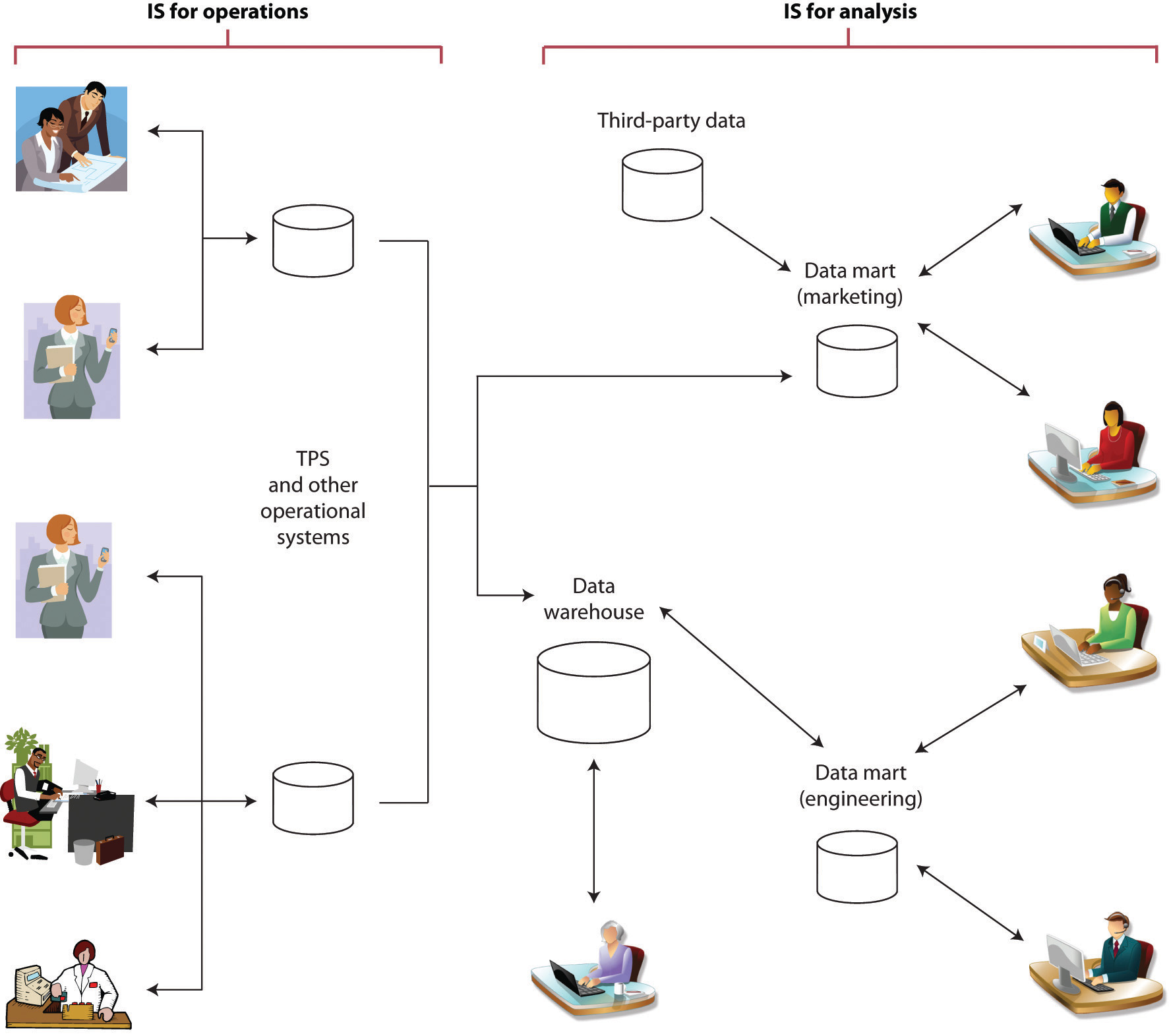
Information systems supporting operations (such as TPS) are typically separate, and “feed” information systems used for analytics (such as data warehouses and data marts).
It’s easy for firms to get seduced by a software vendor’s demonstration showing data at your fingertips, presented in pretty graphs. But as mentioned earlier, getting data in a format that can be used for analytics is hard, complex, and challenging work. Large data warehouses can cost millions and take years to build. Every dollar spent on technology may lead to five to seven more dollars on consulting and other services.R. King, “Intelligence Software for Business,” BusinessWeek podcast, February 27, 2009.
Most firms will face a trade-off—do we attempt a large-scale integration of the whole firm, or more targeted efforts with quicker payoffs? Firms in fast-moving industries or with particularly complex businesses may struggle to get sweeping projects completed in enough time to reap benefits before business conditions change. Most consultants now advise smaller projects with narrow scope driven by specific business goals.D. Rigby and D. Ledingham, “CRM Done Right,” Harvard Business Review, November 2004; and R. King, “Intelligence Software for Business,” BusinessWeek podcast, February 27, 2009.
Firms can eventually get to a unified data warehouse but it may take time. Even analytics king Wal-Mart is just getting to that point. Retail giant Wal-Mart once reported having over seven hundred different data marts and hired Hewlett-Packard for help in bringing the systems together to form a more integrated data warehouse.H. Havenstein, “HP Nabs Wal-Mart as Data Warehousing Customer,” Computerworld, August 1, 2007.
The old saying from the movie Field of Dreams, “If you build it, they will come,” doesn’t hold up well for large-scale data analytics projects. This work should start with a clear vision with business-focused objectives. When senior executives can see objectives illustrated in potential payoff, they’ll be able to champion the effort, and experts agree, having an executive champion is a key success factor. Focusing on business issues will also drive technology choice, with the firm better able to focus on products that best fit its needs.
Once a firm has business goals and hoped-for payoffs clearly defined, it can address the broader issues needed to design, develop, deploy, and maintain its system:Key points adapted from Davenport and J. Harris, Competing on Analytics: The New Science of Winning (Boston: Harvard Business School Press, 2007).
- Data relevance. What data is needed to compete on analytics and to meet our current and future goals?
- Data sourcing. Can we even get the data we’ll need? Where can this data be obtained from? Is it available via our internal systems? Via third-party data aggregators? Via suppliers or sales partners? Do we need to set up new systems, surveys, and other collection efforts to acquire the data we need?
- Data quantity. How much data is needed?
- Data quality. Can our data be trusted as accurate? Is it clean, complete, and reasonably free of errors? How can the data be made more accurate and valuable for analysis? Will we need to ‘scrub,’ calculate, and consolidate data so that it can be used?
- Data hosting. Where will the systems be housed? What are the hardware and networking requirements for the effort?
- Data governance. What rules and processes are needed to manage data from its creation through its retirement? Are there operational issues (backup, disaster recovery)? Legal issues? Privacy issues? How should the firm handle security and access?
For some perspective on how difficult this can be, consider that an executive from one of the largest U.S. banks once lamented at how difficult it was to get his systems to do something as simple as properly distinguishing between men and women. The company’s customer-focused data warehouse drew data from thirty-six separate operational systems—bank teller systems, ATMs, student loan reporting systems, car loan systems, mortgage loan systems, and more. Collectively these legacy systems expressed gender in seventeen different ways: “M” or “F”; “m” or “f”; “Male” or “Female”; “MALE” or “FEMALE”; “1” for man, “0” for woman; “0” for man, “1” for woman and more, plus various codes for “unknown.” The best math in the world is of no help if the values used aren’t any good. There’s a saying in the industry, “garbage in, garbage out.”
Hadoop: Big Insights from Unstructured “Big Data”
Having neatly structured data warehouses and data-marts are great—the tools are reliable and can often be turned over to end-users or specialists who can rapidly produce reports and other analyses. But roughly 80 percent of corporate data is messy and unstructured, and it is not stored in conventional, relational formats—think of data stored in office productivity documents, e-mail, and social media.R. King, “Getting a Handle on Big Data with Hadoop,” BusinessWeek, September 7, 2011. Conventional tools often choke when trying to sift through the massive amounts of data collected by many of today’s firms. The open-source project known as Hadoop was created to analyze massive amounts of raw information better than traditional, highly-structured databases.
Hadoop is made up of some half-dozen separate software pieces and requires the integration of these pieces to work. Hadoop-related projects have names such as Hive, Pig, and Zookeeper. Their use is catching on like wildfire, with some expecting that within five years, more than half of the world’s data will be stored in Hadoop environments.R. King, “Getting a Handle on Big Data with Hadoop,” BusinessWeek, September 7, 2011. Expertise is in short supply, with Hadoop-savvy technologists having lots of career opportunities.
There are four primary advantages to Hadoop:IBM Big Data, “What is Hadoop?” YouTube video, 3:12 May 22, 2012, http://www.youtube.com/watch?v=RQr0qd8gxW8.
- Flexibility: Hadoop can absorb any type of data, structured or not, from any type of source (geeks would say such a system is schema-less). But this disparate data can still be aggregated and analyzed.
- Scalability: Hadoop systems can start on a single PC, but thousands of machines can eventually be combined to work together for storage and analysis.
- Cost effectiveness: Since the system is open source and can be started with low-end hardware, the technology is cheap by data-warehousing standards. Many vendors also offer Hadoop as a cloud service, allowing firms to avoid hardware costs altogether.
- Fault tolerance: One of the servers running your Hadoop cluster just crashed? No big deal. Hadoop is designed in such a way so that there will be no single point of failure. The system will continue to work, relying on the remaining hardware.
Financial giant Morgan Stanley is a big believer in Hadoop. One senior technology manager at the firm contrasts Hadoop with highly structured systems, saying that in the past, “IT asked the business what they want, creates a data structure and writes structured query language, sources the data, conforms it to the table and writes a structured query. Then you give it to them and they often say that is not what they wanted.” But with Hadoop overseeing a big pile of unstructured (or less structured) data, technical staff can now work with users to carve up and combine data in lots of different ways, or even set systems loose in the data to hunt for unexpected patterns (see the discussion of data mining later in this chapter). Morgan Stanley’s initial Hadoop experiments started with a handful of old servers that were about to be retired, but the company has steadily ramped up its efforts. Now by using Hadoop, the firm sees that it is able to analyze data on a far larger scale (“petabytes of data, which is unheard of in the traditional database world”) with potentially higher-impact results. The bank is looking at customers’ financial objectives and trying to come up with investment insights to help them invest appropriately, and it is seeking “Big Data” insights to help the firm more effectively manage risk.T. Groenfeldt, “Morgan Stanley takes on Big Data with Hadoop,” Forbes, May 30, 2012.
Figure 11.3 The Hadoop Logo

The project was named after a toy elephant belonging to the son of Hadoop Developer Doug Cutting.
Other big name-firms using Hadoop for “Big Data” insights include Bank of America, Disney, GE, LinkedIn, Nokia, Twitter, and Wal-Mart. Hadoop is an open source project overseen by the Apache Software Foundation. It has an Internet pedigree and is based on ideas by Google and lots of software contributed by Yahoo! (two firms that regularly need to dive into massive and growing amounts of unstructured data—web pages, videos, images, social media, user account information, and more). IBM used Hadoop as the engine that helped power Watson to defeat human opponents on Jeopardy, further demonstrating the technology’s ability to analyze wildly different data for accurate insight. Other tech firms embracing Hadoop and offering some degree of support for the technology include HP, EMC, and Microsoft.
E-discovery: Supporting Legal Inquiries
Data archiving isn’t just for analytics. Sometimes the law requires organizations to dive into their electronic records. E-discoveryThe process of identifying and retrieving relevant electronic information to support litigation efforts. refers to identifying and retrieving relevant electronic information to support litigation efforts. E-discovery is something a firm should account for in its archiving and data storage plans. Unlike analytics that promise a boost to the bottom line, there’s no profit in complying with a judge’s order—it’s just a sunk cost. But organizations can be compelled by court order to scavenge their bits, and the cost to uncover difficult to access data can be significant, if not planned for in advance.
In one recent example, the Office of Federal Housing Enterprise Oversight (OFHEO) was subpoenaed for documents in litigation involving mortgage firms Fannie Mae and Freddie Mac. Even though the OFHEO wasn’t a party in the lawsuit, the agency had to comply with the search—an effort that cost $6 million, a full 9 percent of its total yearly budget.A. Conry-Murray, “The Pain of E-discovery,” InformationWeek, June 1, 2009.
Key Takeaways
- Data warehouses and data marts are repositories for large amounts of transactional data awaiting analytics and reporting.
- Large data warehouses are complex, can cost millions, and take years to build.
- The open source Hadoop effort provides a collection of technologies for manipulating massive amounts of unstructured data. The system is flexible, saleable, cost-effective, and fault-tolerant. Hadoop grew from large Internet firms but is now being used across industries.
Questions and Exercises
- List the issues that need to be addressed in order to design, develop, deploy, and maintain data warehouses and data marts.
- What is meant by “data relevance”?
- What is meant by “data governance”?
- What is the difference between a data mart and a data warehouse?
- Why are data marts and data warehouses necessary? Why can’t an organization simply query its transactional database?
- How can something as simple as customer gender be difficult to for a large organization to establish in a data warehouse?
- What is Hadoop? Why would a firm use Hadoop instead of conventional data warehousing and data mart technologies?
- Research the current state of “Big Data” analysis. Identify major firms leveraging Hadoop or similar technologies and share high-impact examples with your classmates and professor.