This is “The Business Intelligence Toolkit”, section 11.6 from the book Getting the Most Out of Information Systems: A Manager's Guide (v. 1.0). For details on it (including licensing), click here.
For more information on the source of this book, or why it is available for free, please see the project's home page. You can browse or download additional books there. To download a .zip file containing this book to use offline, simply click here.



11.6 The Business Intelligence Toolkit
Learning Objectives
After studying this section you should be able to do the following:
- Know the tools that are available to turn data into information.
- Identify the key areas where businesses leverage data mining.
- Understand some of the conditions under which analytical models can fail.
- Recognize major categories of artificial intelligence and understand how organizations are leveraging this technology.
So far we’ve discussed where data can come from, and how we can get data into a form where we can use it. But how, exactly, do firms turn that data into information? That’s where the various software tools of business intelligence (BI) and analytics come in. Potential products in the business intelligence toolkit range from simple spreadsheets to ultrasophisticated data mining packages leveraged by teams employing “rocket-science” mathematics.
Query and Reporting Tools
The idea behind query and reporting tools is to present users with a subset of requested data, selected, sorted, ordered, calculated, and compared, as needed. Managers use these tools to see and explore what’s happening inside their organizations.
Canned reportsReports that provide regular summaries of information in a predetermined format. provide regular summaries of information in a predetermined format. They’re often developed by information systems staff and formats can be difficult to alter. By contrast, ad hoc reporting toolsTools that put users in control so that they can create custom reports on an as-needed basis by selecting fields, ranges, summary conditions, and other parameters. allow users to dive in and create their own reports, selecting fields, ranges, and other parameters to build their own reports on the fly. DashboardsA heads-up display of critical indicators that allow managers to get a graphical glance at key performance metrics. provide a sort of heads-up display of critical indicators, letting managers get a graphical glance at key performance metrics. Some tools may allow data to be exported into spreadsheets. Yes, even the lowly spreadsheet can be a powerful tool for modeling “what if” scenarios and creating additional reports (of course be careful, if data can be easily exported then it can potentially leave the firm dangerously exposed, raising privacy, security, legal, and competitive concerns).
Figure 11.3 The Federal IT Dashboard
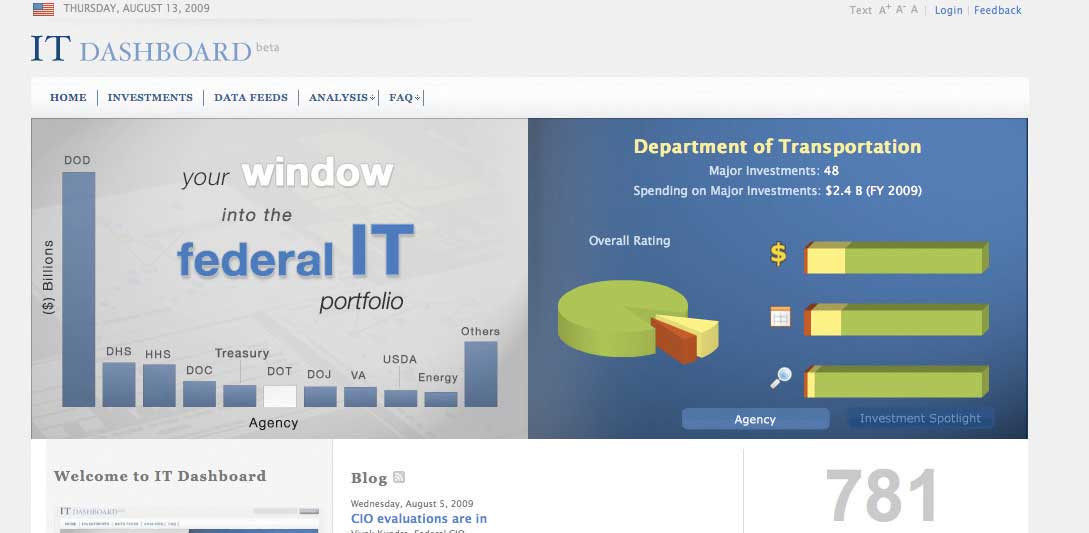
The Federal IT dashboard offers federal agencies, and the general public, information about the government’s IT investments.
A subcategory of reporting tools is referred to as online analytical processing (OLAP)A method of querying and reporting that takes data from standard relational databases, calculates and summarizes the data, and then stores the data in a special database called a data cube. (pronounced “oh-lap”). Data used in OLAP reporting is usually sourced from standard relational databases, but it’s calculated and summarized in advance, across multiple dimensions, with the data stored in a special database called a data cubeA special database used to store data in OLAP reporting.. This extra setup step makes OLAP fast (sometimes one thousand times faster than performing comparable queries against conventional relational databases). Given this kind of speed boost, it’s not surprising that data cubes for OLAP access are often part of a firm’s data mart and data warehouse efforts.
Figure 11.4
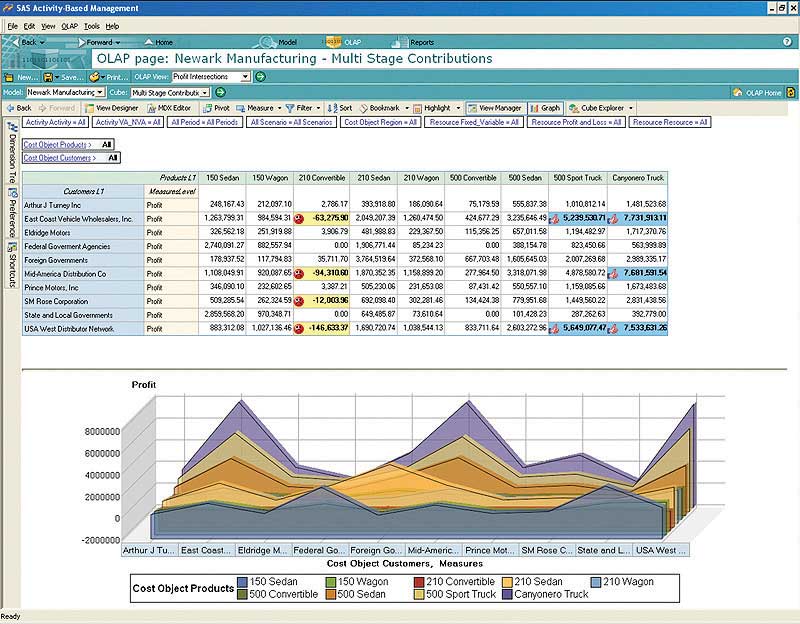
This OLAP report compares multiple dimensions. Company is along the vertical axis, and product is along the horizontal access. Many OLAP tools can also present graphs of multidimensional data.
Copyright © 2009 SAS Institute, Inc.
A manager using an OLAP tool can quickly explore and compare data across multiple factors such as time, geography, product lines, and so on. In fact, OLAP users often talk about how they can “slice and dice” their data, “drilling down” inside the data to uncover new insights. And while conventional reports are usually presented as summarized list of information, OLAP results look more like a spreadsheet, with the various dimensions of analysis in rows and columns, with summary values at the intersection.
Public Sector Reporting Tools in Action: Fighting Crime and Fighting Waste
Access to ad hoc query and reporting tools can empower all sorts of workers. Consider what analytics tools have done for the police force in Richmond, Virginia. The city provides department investigators with access to data from internal sources such as 911 logs and police reports, and combines this with outside data including neighborhood demographics, payday schedules, weather reports, traffic patterns, sports events, and more.
Experienced officers dive into this data, exploring when and where crimes occur. These insights help the department decide how to allocate its limited policing assets to achieve the biggest impact. While IT staffers put the system together, the tools are actually used by officers with expertise in fighting street crime—the kinds of users with the knowledge to hunt down trends and interpret the causes behind the data. And it seems this data helps make smart cops even smarter—the system is credited with delivering a single-year crime-rate reduction of 20 percent.S. Lohr, “Reaping Results: Data-Mining Goes Mainstream,” New York Times, May 20, 2007.
As it turns out, what works for cops also works for bureaucrats. When administrators for Albuquerque were given access to ad hoc reporting systems, they uncovered all sorts of anomalies, prompting excess spending cuts on everything from cell phone usage to unnecessarily scheduled overtime. And once again, BI performed for the public sector. The Albuquerque system delivered the equivalent of two million dollars in savings in just the first three weeks it was used.R. Mulcahy, “ABC: An Introduction to Business Intelligence,” CIO, March 6, 2007.
Data Mining
While reporting tools can help users explore data, modern datasets can be so large that it might be impossible for humans to spot underlying trends. That’s where data mining can help. Data miningThe process of using computers to identify hidden patterns in, and to build models from, large data sets. is the process of using computers to identify hidden patterns and to build models from large data sets.
Some of the key areas where businesses are leveraging data mining include the following:
- Customer segmentation—figuring out which customers are likely to be the most valuable to a firm.
- Marketing and promotion targeting—identifying which customers will respond to which offers at which price at what time.
- Market basket analysis—determining which products customers buy together, and how an organization can use this information to cross-sell more products or services.
- Collaborative filtering—personalizing an individual customer’s experience based on the trends and preferences identified across similar customers.
- Customer churn—determining which customers are likely to leave, and what tactics can help the firm avoid unwanted defections.
- Fraud detection—uncovering patterns consistent with criminal activity.
- Financial modeling—building trading systems to capitalize on historical trends.
- Hiring and promotion—identifying characteristics consistent with employee success in the firm’s various roles.
For data mining to work, two critical conditions need to be present: (1) the organization must have clean, consistent data, and (2) the events in that data should reflect current and future trends. The recent financial crisis provides lessons on what can happen when either of these conditions isn’t met.
First lets look at problems with using bad data. A report in the New York Times has suggested that in the period leading up to the 2008 financial crisis, some banking executives deliberately deceived risk management systems in order to skew capital-on-hand requirements. This deception let firms load up on risky debt, while carrying less cash for covering losses.S. Hansell, “How Wall Street Lied to Its Computers,” New York Times, September 18, 2008. Deceive your systems with bad data and your models are worthless. In this case, wrong estimates from bad data left firms grossly overexposed to risk. When debt defaults occurred; several banks failed, and we entered the worst financial crisis since the Great Depression.
Now consider the problem of historical consistency: Computer-driven investment models can be very effective when the market behaves as it has in the past. But models are blind when faced with the equivalent of the “hundred-year flood” (sometimes called “black swans”); events so extreme and unusual that they never showed up in the data used to build the model.
We saw this in the late 1990s with the collapse of the investment firm Long Term Capital Management. LTCM was started by Nobel Prize–winning economists, but when an unexpected Russian debt crisis caused the markets to move in ways not anticipated by its models, the firm lost 90 percent of its value in less than two months. The problem was so bad that the Fed had to step in to supervise the firm’s multibillion-dollar bailout. Fast forward a decade to the banking collapse of 2008, and we again see computer-driven trading funds plummet in the face of another unexpected event—the burst of the housing bubble.P. Wahba, “Buffeted ‘Quants’ Are Still in Demand,” Reuters, December 22, 2008.
Data mining presents a host of other perils, as well. It’s possible to over-engineerBuild a model with so many variables that the solution arrived at might only work on the subset of data you’ve used to create it. a model, building it with so many variables that the solution arrived at might only work on the subset of data you’ve used to create it. You might also be looking at a random but meaningless statistical fluke. In demonstrating how flukes occur, one quantitative investment manager uncovered a correlation that at first glance appeared statistically to be a particularly strong predictor for historical prices in the S&P 500 stock index. That predictor? Butter production in Bangladesh.P. Coy, “He Who Mines Data May Strike Fool’s Gold,” BusinessWeek, June 16, 1997. Sometimes durable and useful patterns just aren’t in your data.
One way to test to see if you’re looking at a random occurrence in the numbers is to divide your data, building your model with one portion of the data, and using another portion to verify your results. This is the approach Netflix has used to test results achieved by teams in the Netflix Prize, the firm’s million-dollar contest for improving the predictive accuracy of its movie recommendation engine (see Chapter 3 "Netflix: David Becomes Goliath").
Finally, sometimes a pattern is uncovered but determining the best choice for a response is less clear. As an example, let’s return to the data-mining wizards at Tesco. An analysis of product sales data showed several money-losing products, including a type of bread known as “milk loaf.” Drop those products, right? Not so fast. Further analysis showed milk loaf was a “destination product” for a loyal group of high-value customers, and that these customers would shop elsewhere if milk loaf disappeared from Tesco shelves. The firm kept the bread as a loss-leader and retained those valuable milk loaf fans.B. Helm, “Getting Inside the Customer’s Mind,” BusinessWeek, September 11, 2008. Data miner beware—first findings don’t always reveal an optimal course of action.
This last example underscores the importance of recruiting a data mining and business analytics team that possesses three critical skills: information technology (for understanding how to pull together data, and for selecting analysis tools), statistics (for building models and interpreting the strength and validity of results), and business knowledge (for helping set system goals, requirements, and offering deeper insight into what the data really says about the firm’s operating environment). Miss one of these key functions and your team could make some major mistakes.
While we’ve focused on tools in our discussion above, many experts suggest that business intelligence is really an organizational processes as much as it is a set of technologies. Having the right team is critical in moving the firm from goal setting through execution and results.
Artificial Intelligence
Data Mining has its roots in a branch of computer science known as artificial intelligence (or AI). The goal of AI is create computer programs that are able to mimic or improve upon functions of the human brain. Data mining can leverage neural networksAn AI system that examines data and hunts down and exposes patterns, in order to build models to exploit findings. or other advanced algorithms and statistical techniques to hunt down and expose patterns, and build models to exploit findings.
Expert systemsAI systems that leverages rules or examples to perform a task in a way that mimics applied human expertise. are AI systems that leverage rules or examples to perform a task in a way that mimics applied human expertise. Expert systems are used in tasks ranging from medical diagnoses to product configuration.
Genetic algorithmsModel building techniques where computers examine many potential solutions to a problem, iteratively modifying (mutating) various mathematical models, and comparing the mutated models to search for a best alternative. are model building techniques where computers examine many potential solutions to a problem, iteratively modifying (mutating) various mathematical models, and comparing the mutated models to search for a best alternative. Genetic algorithms have been used to build everything from financial trading models to handling complex airport scheduling, to designing parts for the international space station.Adapted from J. Kahn, “It’s Alive,” Wired, March 2002; O. Port, “Thinking Machines,” BusinessWeek, August 7, 2000; and L. McKay, “Decisions, Decisions,” CRM Magazine, May 1, 2009.
While AI is not a single technology, and not directly related to data creation, various forms of AI can show up as part of analytics products, CRM tools, transaction processing systems, and other information systems.
Key Takeaways
- Canned and ad hoc reports, digital dashboards, and OLAP are all used to transform data into information.
- OLAP reporting leverage data cubes, which take data from standard relational databases, calculating and summarizing data for super-fast reporting access. OLAP tools can present results through multidimensional graphs, or via spreadsheet-style cross-tab reports.
- Modern datasets can be so large that it might be impossible for humans to spot underlying trends without the use of data mining tools.
- Businesses are using data mining to address issues in several key areas including customer segmentation, marketing and promotion targeting, collaborative filtering, and so on.
- Models influenced by bad data, missing or incomplete historical data, and over-engineering are prone to yield bad results.
- One way to test to see if you’re looking at a random occurrence in your data is to divide your data, building your model with one portion of the data, and using another portion to verify your results.
- Analytics may not always provide the total solution for a problem. Sometimes a pattern is uncovered, but determining the best choice for a response is less clear.
- A competent business analytics team should possess three critical skills: information technology, statistics, and business knowledge.
Questions and Exercises
- What are some of the tools used to convert data into information?
- What is the difference between a canned reports and an ad hoc reporting?
- How do reports created by OLAP differ from most conventional reports?
- List the key areas where businesses are leveraging data mining.
- What is market basket analysis?
- What is customer churn?
- For data mining to work, what two critical data-related conditions must be present?
- Discus occurrences of model failure caused by missing or incomplete historical data.
- Discuss Tesco’s response to their discovery that “milk loaf” was a money-losing product.
- List the three critical skills a competent business analytics team should possess.
- Do any of the products that you use leverage artificial intelligence? What kinds of AI might be used in Netflix’s movie recommendation system, Apple’s iTunes Genius playlist builder, or Amazon’s Web site personalization? What kind of AI might help a physician make a diagnosis or help an engineer configure a complicated product in the field?